
记ElasticSearch的一个有趣的性能问题
背景
笔者近期在做一个电商的交易模块,项目中订单相关的信息存储在ElasticSearch中,除去搜索的用途外,由于分布式数据库的sharding字段只有一个,还兼职根据某个特定字段找到某一张订单,避免全表扫描。
在对一批接口压测时,发现有个接口A性能非常弱,比较有趣的是,这个接口对ElasticSearch的查询条件与同一批的另一个接口B在某个场景下基本一致,但QPS差异巨大,
且A接口压测时ElasticSearch CPU飙升,而B接口压测时维持在很低的水平。
猜测
在排查过代码之后,发现两者的查询条件基本一致,但是A接口查询时使用了一个elasticsearchRestTemplate.queryForList方法,而B接口则是elasticsearchRestTemplate.queryForPage,
这两个方法的区别在于分不分页,然而,queryForList内部由于es的限制实际上也是分页查询,只是设置默认最大分页大小10000,简单修改后重新压测,发现问题解决了。
理论上到此为止已经解决问题了,但是为什么?明明无论是设置分页大小为10或10000,返回的数据量都是一致的(1-3条左右),为什么性能会有这么大的差异?
问题在哪儿?
在简单了解了一下ElasticSearch的搜索和分页机制后,猜测分页大小的10000可能导致es在某个环节分配了过量的内存,导致内存飙升进而触发gc占用cpu,最后影响吞吐量。
然而在初步分析了代码后,发现这个猜测并不成立,因为es的reduce阶段是在返回数据之后进行的,且最后创建的结果队列是根据实际大小创建的。
观察es的监控发现gc确实频繁,还是dump一下看看。
1.使用elasticsearchRestTemplate.queryForPage时的heap信息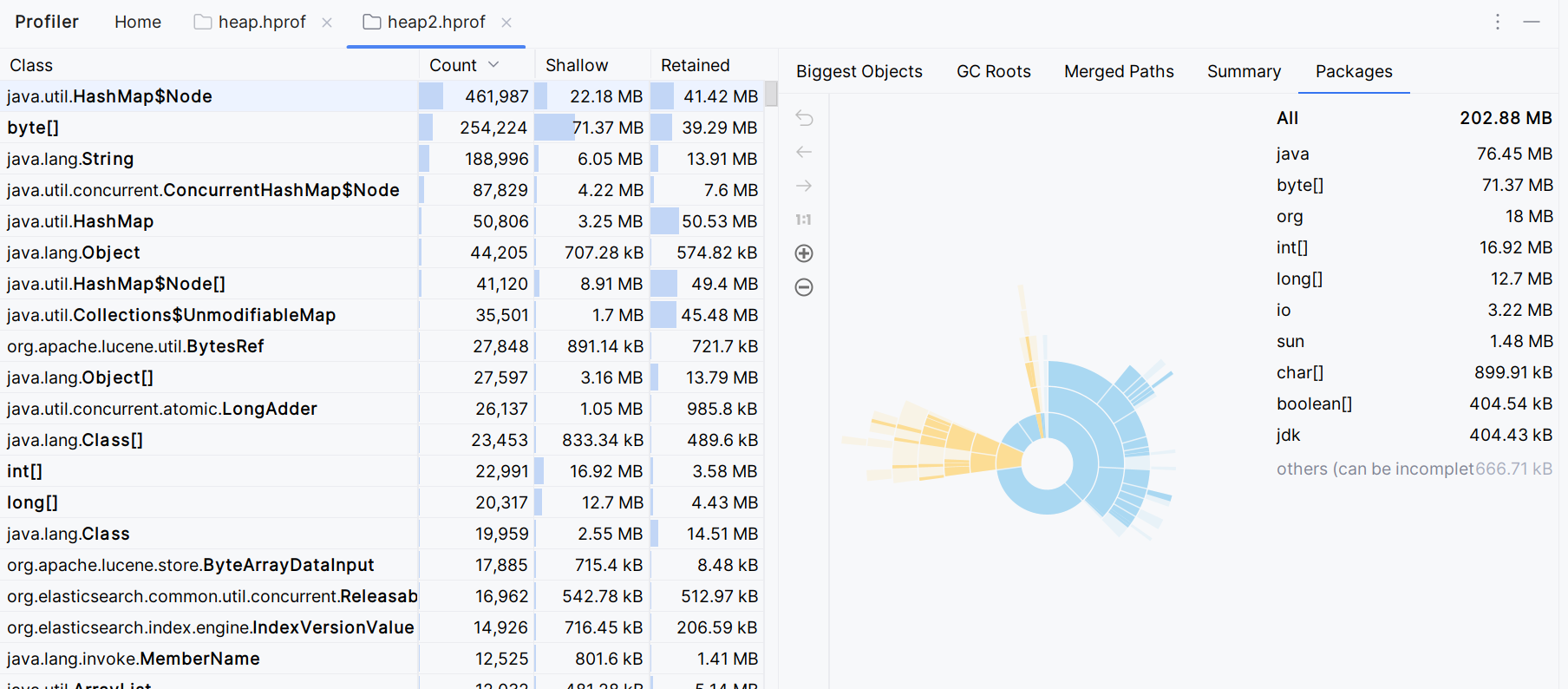
2.使用elasticsearchRestTemplate.queryForList时的heap信息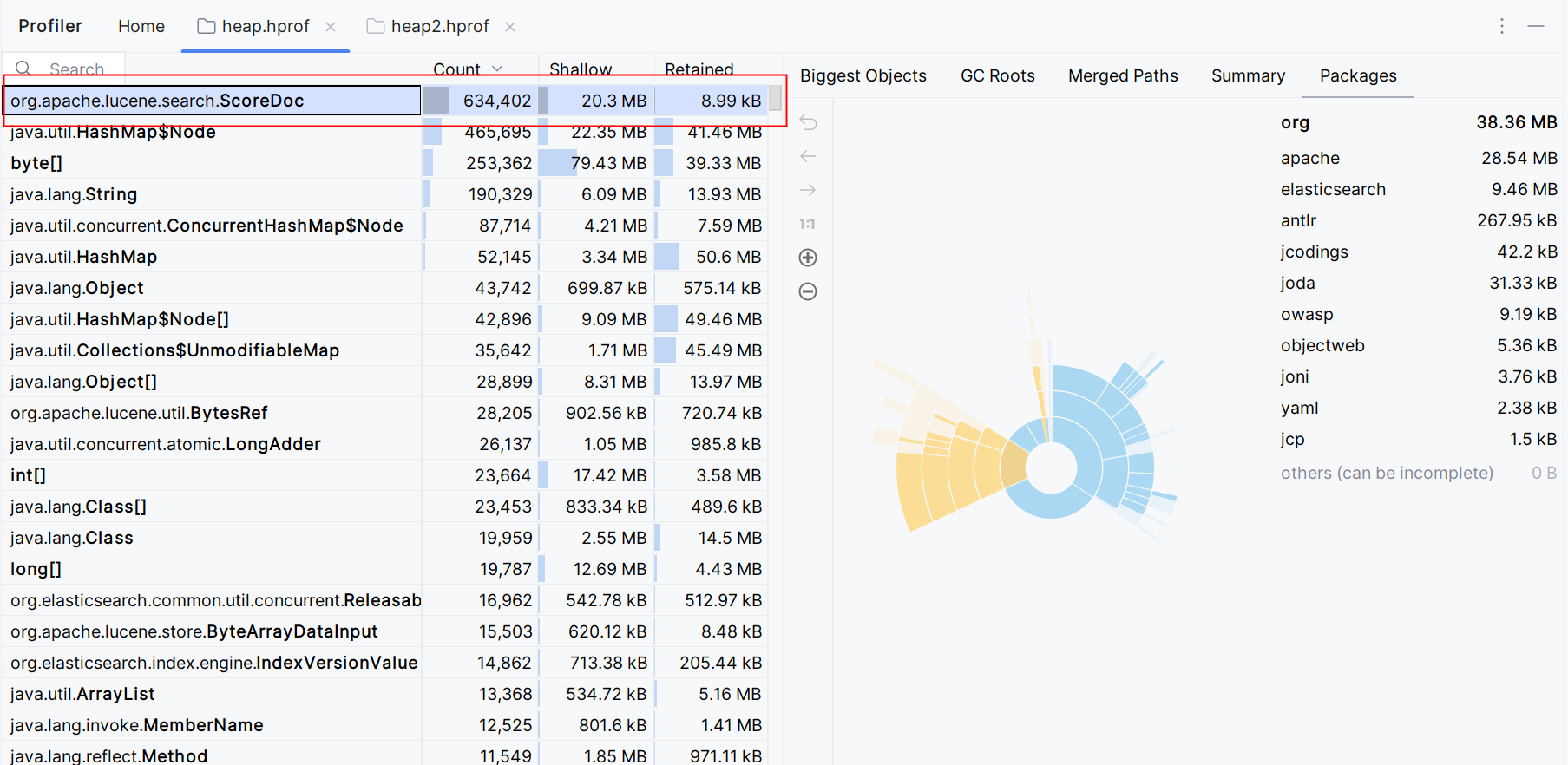
从两者的heap信息中可以看到org.apache.lucene.search.ScoreDoc的数量和内存占用都很大,ScoreDoc是lucene中的一个类,用于存储文档的id和评分,而这个评分是在搜索时计算的,
进一步查看,发现这些ScoreDoc很多来源于一个奇怪的数组。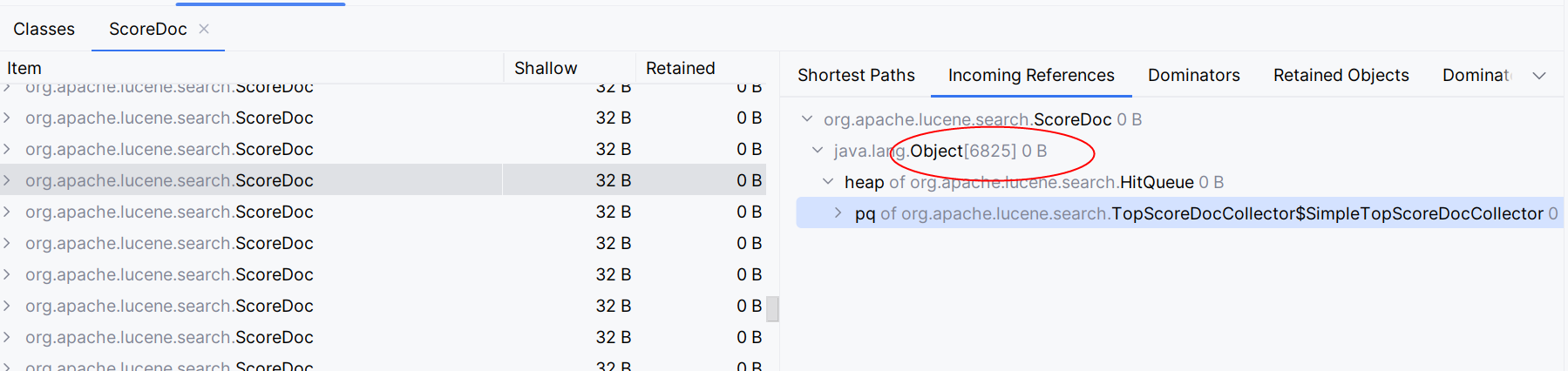
问题的原因
根据heap信息发现问题在HitQueue,而HitQueue继承了PriorityQueue,PriorityQueue是一个二叉堆,用于搜索时排序。当使用queryForList时,由于分页大小为10000,导致了HitQueue的大小为10000,
内部创建了一个大小同样为10000的数组,并且比较糟糕的是,创建好数据的同步也创建了10000个ScoreDoc对象。这两者产生了大量的内存占用。
1 | final class HitQueue extends PriorityQueue<ScoreDoc> { |
总结
在lucene的issue中,确实也有人提过关于这个issue的优化方案,截至目前,这个修复还没有合并到lucene的主分支中。
Binary heaps of Objects in Java does not scale well:
The HitQueue uses 28 bytes/element and memory access is scattered due to the binary heap algorithm and the use of Objects.
To make matters worse, the use of sentinel objects means that even if only a tiny number of documents matches,
the full amount of Objects is still allocated.
Java中的二进制堆对象扩展性不好:HitQueue使用28字节/元素,由于二进制堆算法和对象的使用,内存访问是分散的。更糟糕的是,使用哨兵对象意味着即使只有少量的文档匹配,仍然会分配全部的对象。
lucene选择使用事先创建好的小对象固定大小数组来存储搜索结果而非动态扩容的ArrayList,这样做的好处是可以避免动态扩容的开销,这个行为很容易理解,对于搜索场景,命中的结果总是
很多的。对于A接口的使用场景性能不佳其实是可以预见的。如果使用动态扩容在事实上会损害lucene的搜索性能。所以其实该问题并不是elasticsearch或者lucene的问题,而是单纯的使用方式有误
说几句不负责任的话:
在设置分页大小较大如10000然后固定命中较小的结果集时elasticsearch的性能急剧下降并非中间件的问题,然而代码使用方也没有明显的过错,
毕竟elasticsearchRestTemplate提供了queryForList这个api,这个api设计的含义是一次性返回所有结果,然后该api不仅没有满足语义(最多返回10000条),
而且有严重的性能问题,这是一个设计上的失误。
取消这个api可能是最好的选择。。。

