risc-v控制时钟中断只需要用到mtime and mtimecmp两个寄存器,其中mtime是一个实时计数器,以恒定的频率自增(取决于时钟频率,例如1 MHz,那么每秒钟mtime寄存器的值就会增加1000000)。 mtimecmp则是一个预设的值,当mtime=mtimecmp且MIE中始终中断开启时时会触发一次时钟中断,借由这两个寄存器就可以实现自定义间隔的时钟中断。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
start_kernel()(init/main.c) time_init()(arch/riscv/kernel/time.c) ... tick_setup_device()(kernel/time/tick-common.c) /* * 设置一个周期性的tick * Setup the device for a periodic tick */ tick_setup_periodic()(kernel/time/tick-common.c) clockevents_program_event()(kernel/time/clockevents.c) riscv_clock_next_event()(drivers/clocksource/timer-riscv.c) { //开启始终中断 csr_set(CSR_IE, IE_TIE); //通过SBI设置mtimecmp,引发第一次tick sbi_set_timer(get_cycles64() + delta); return0; } }
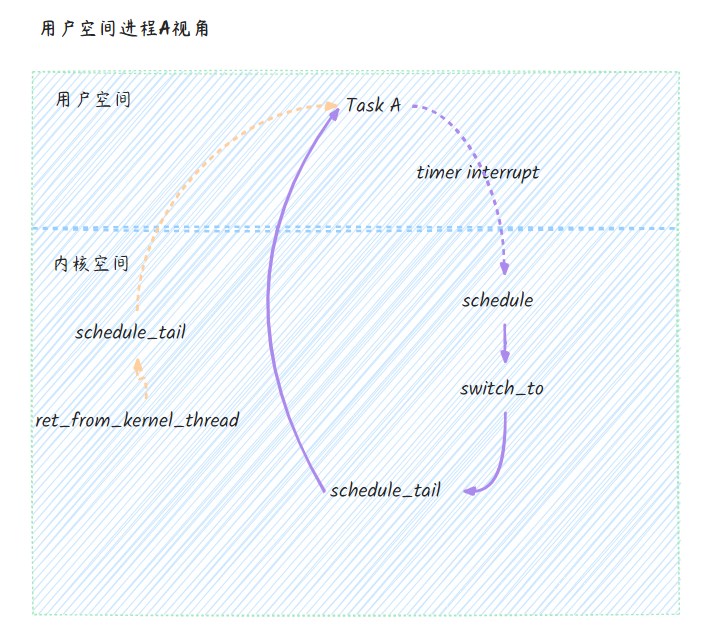
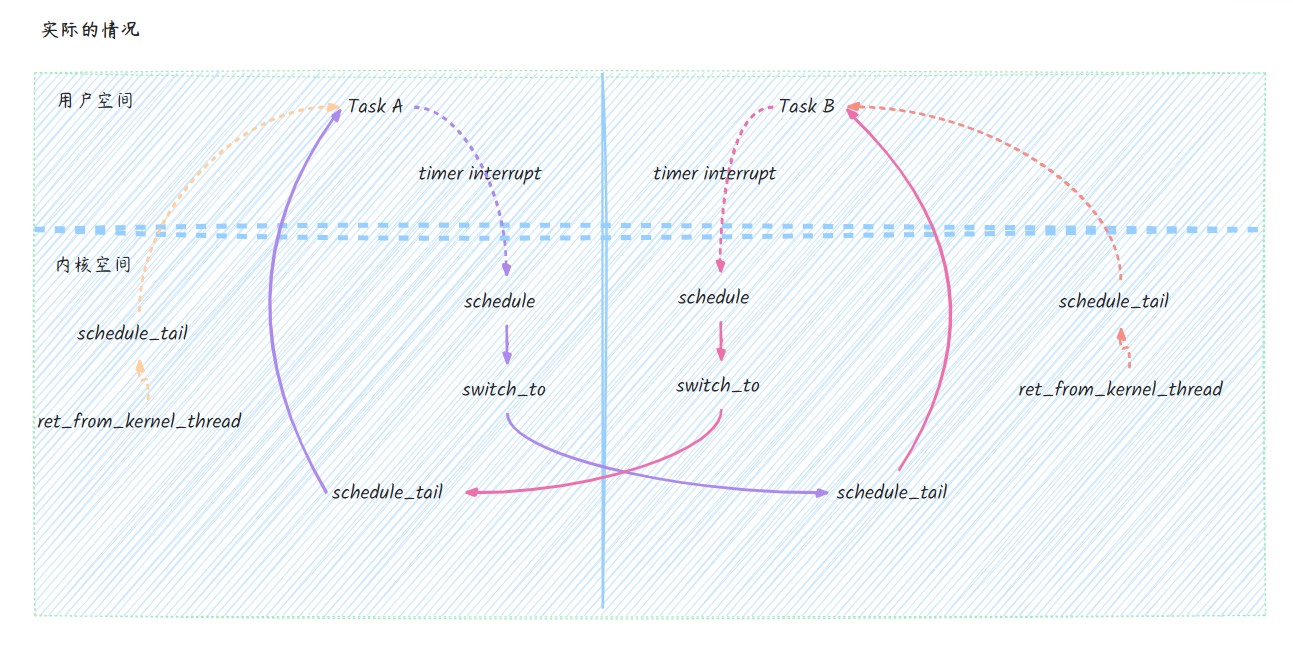
generic_handle_arch_irq()(kernel/irq/handle.c) riscv_intc_irq()(drivers/irqchip/irq-riscv-intc.c) generic_handle_domain_irq()(kernel/irq/irqdesc.c) handle_irq_desc()(kernel/irq/irqdesc.c) generic_handle_irq_desc(include/linux/irqdesc.h) riscv_timer_interrupt()(drivers/clocksource/timer-riscv.c) clockevents_program_event()(kernel/time/clockevents.c) /* * Setup the next period for devices, which do not have * periodic mode: * 其中TICK_NSEC=((NSEC_PER_SEC+HZ/2)/HZ) */ next = ktime_add_ns(next, TICK_NSEC); //设置下一次tick的时间 riscv_clock_next_event()(drivers/clocksource/timer-riscv.c) evdev->event_handler(evdev); tick_handle_periodic()(kernel/time/tick-common.c) tick_periodic()()(kernel/time/tick-common.c) update_process_times()(kernel/time/timer.c) scheduler_tick()(kernel/sched/core.c) //调度器的tick函数 curr->sched_class->task_tick(rq, curr, 0); //这里调用CFS的task_tick task_tick_fair()(kernel/sched/fair.c) /* * Update run-time statistics of the 'current'. */ update_curr(cfs_rq); if (cfs_rq->nr_running > 1) check_preempt_tick(cfs_rq, curr); ideal_runtime = sched_slice(cfs_rq, curr); delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime; // 时间片用完,设置TIF_NEED_RESCHED标识 if (delta_exec > ideal_runtime) { resched_curr(rq_of(cfs_rq)); set_tsk_need_resched() (kernel/sched/core.c) set_tsk_thread_flag(tsk,TIF_NEED_RESCHED); /* * The current task ran long enough, ensure it doesn't get * re-elected due to buddy favours. */ clear_buddies(cfs_rq, curr); return; }