
如何设计一个高性能的短链接系统
背景
做为刚转正的实习生,最后在PM的指导下设计了一款短链接系统,这里记录一下设计思路和实现细节。
设计思路
短链接其实很简单,只要将长链接通过某种算法转换成短链接,然后通过短链接重定向到长链接即可。
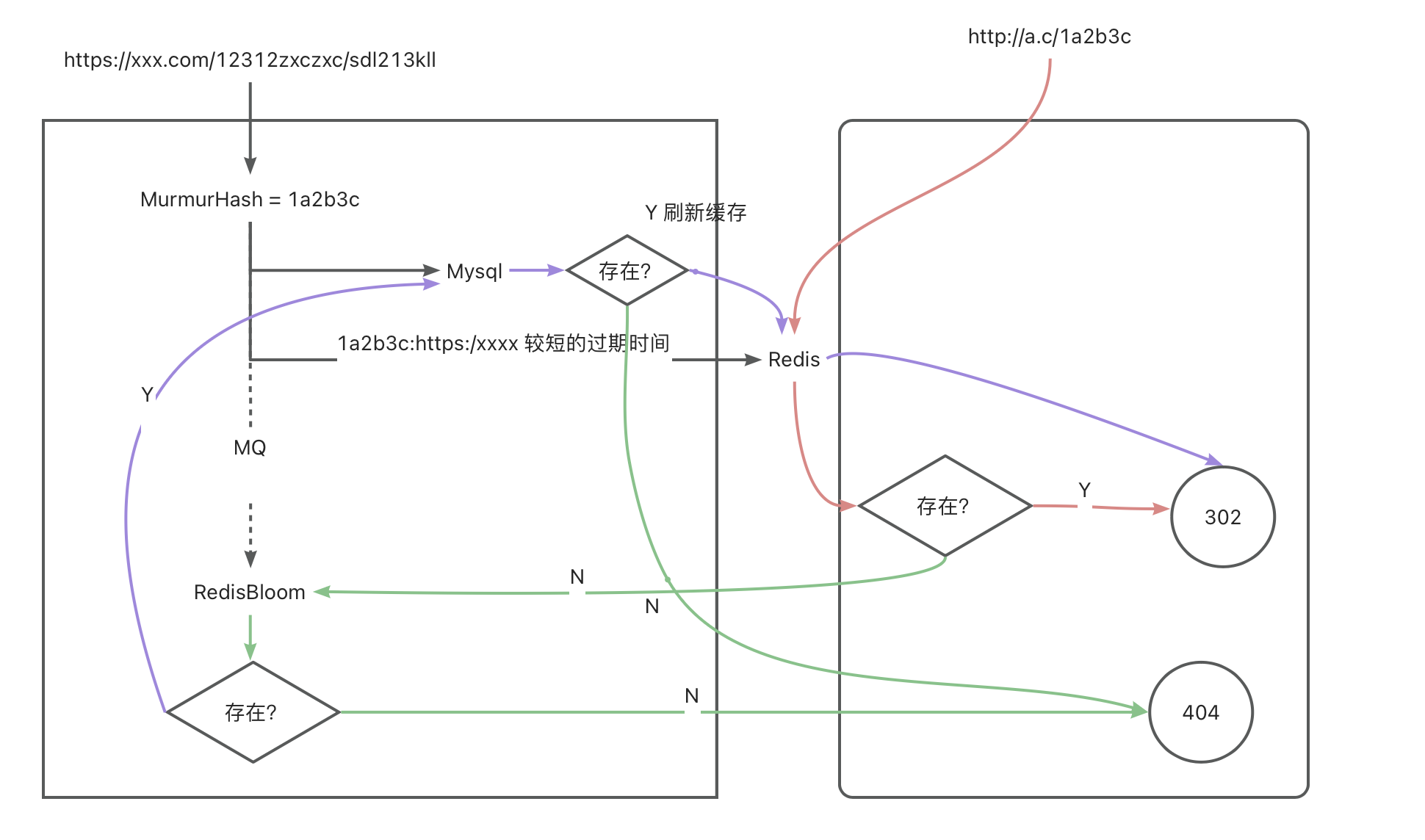
设计思路很简单,直接使用一个接口/create创建短链接,并在数据库中存储长链接和短链接的映射关系。
另一个/${hashcode}接口用于访问,通过短链接重定向到长链接。
创建短链接
创建短链接的接口很简单,直接将长链接转换6位短链接,直接插入并使用数据库唯一键约束,如果短链接已经存在,则对比长链接是否一致,一致返回即可,
不一致则是发生了碰撞。在长链接后拼接随机字符即可(入库的还是原链接)。
考虑到刚创建的链接可能会被频繁访问,所以我们在创建链接的时候就将短链接放入Redis缓存中,并设置缓存时间为有效期,这样可以减少数据库的访问。
数据库字段:
- long_url: 长链接
- tiny_url: 短链接
- create_time: 创建时间
- update_time: 更新时间
- status: 状态
短链接生成算法
对于短链接生成算法,可以使用数据库id自增或者雪花算法,也可以使用hash算法,将长链接转换成hash值,然后再将hash值转换成62进制的字符串。
前者的优点是简单而且性能高,但是保密性不好,因为用户可以通过递增的方式遍历所有的短链接。
后者的优点是随机性好但性能略差,而且有可能发生hash碰撞。
这里我们选择hash算法,毕竟马上就会被用于不记名发奖,要是被人遍历出来偷走奖品就完蛋了。
1.MD5算法,MD5算法是最常见的hash算法,随机性好
2.SHA1算法,对于长度小于2^64位的消息,SHA1会产生一个160位的消息摘要
3.MurmurHash算法,MurmurHash是一种非加密型哈希函数,适用于一般的哈希检索操作,对于规律性分布强的key,MurmurHash的随机分布特征表现更良好。
最终我们选择了MurmurHash算法,因为短链接的规律性,使用MurmurHash的碰撞几率要小很多,而且对于短链接场景性能更好。
短链接位数选择
根据业务需求,观察现有分享链接的qps,我们选择预留5年的容量约5亿,6位短链接,这样可以支持62^6=568亿个链接,基本够用了。
MurmurHash3可以生成32位/128位的hash值,我们选择32位的hash值,然后再将32位的hash值转换成62进制的字符串,这样其实浪费了一些空间(32位只有43亿),但是为了简单,我们选择了这种方式。
转换方式如下所示:
1 | package main |
访问短链接
访问短链接的接口也很简单,直接通过短链接查询Redis,然后重定向到长链接即可(Redis中不存在可直接返回404,因为缓存失效后有效期也失效了)。
性能优化
以上方案做为一个小型的短链接系统已经足够了,但是为了更好的性能,我们还可以做一些优化。
服务拆分
短链接是非常极端的读多写少场景,将创建短链接和访问短链接的接口拆分成两个服务,访问短链接的服务可以使用golang实现,可以通过k8s的策略快速拉起和节省内存(JAVA启动和预热也太慢了)。
缓存优化
为了避免访问服务查询数据库,我们选择了将短链接的整个生命周期放入缓存,但是这样会导致缓存的数据量过大,16G的节点只能存储0.5kb*32m个key。
怎么办呢,只能降低缓存的时间,当缓存过期时,访问创建服务提供的接口查询数据库并刷新缓存。
数据库优化
1.分表 对于43亿的预估数据量,一共分为63张表,每张表大约有7千万的数据量,这样可以保证单表的查询/插入性能,分表键为hashcode。
同时,要有后台任务及时将过期数据迁移到历史库中,这样可以保证数据库的性能。
布隆过滤器
还有没有更大的优化空间呢?当然有,那就是布隆过滤器。
布隆过滤器是一种数据结构,对于给定的数据集合,它可以告诉你这个数据是否一定不存在,或者可能存在。布隆过滤器的核心是一个位数组和多个hash函数,当一个元素被加入集合时,通过多个hash函数将这个元素映射成位数组中的多个点,查询时通过多个hash函数将查询元素映射成位数组中的多个点,如果所有的点都是1,则说明这个元素可能存在,如果有一个点是0,则说明这个元素一定不存在。
在这里访问数据库有两种场景:
其一是创建时的短链接冲突,由于创建服务qps较低,所以可以直接访问数据库,并且将短链接放入布隆过滤器。
其二是访问短链接,这个场景的qps较高,所以访问短链接时先查缓存,缓存不存在时查询布隆过滤器,如果不存在直接返回404,如果存在再查询数据库。
布隆过滤器的选型
布隆过滤器的选型有很多,比如guava的布隆过滤器,但是guava的布隆过滤器是单机的,我们选择了Redis的布隆过滤器,因为我们的系统是分布式的,而且Redis的布隆过滤器是原生支持的(2019发布的RedisBloom)。
布隆过滤器的参数选择
在这里我们直接使用redisBloom创建,误差率为0.001,容量为1亿,实测占用内存约为200M,并且redisBloom支持动态扩容(倍增式扩容/O(k)级性能开销),所以不用担心容量不够或误判率上升。
最后,考虑到redis的高可用,我们需要给redis访问和写入做降级服务,且在redis数据丢失或系统长期运行redisBloom容量增加但是大部分都是过期key的情况下,需要有后台任务定期重建布隆过滤器。
这样,我们的短链接系统就设计完了。

